

8B 模子在数学竞赛任务上卓绝 GPT-5!
阶跃星辰阐发推出并行协同推理(PaCoRe, Parallel Coordinated Reasoning),这是一个全新的教练和推理框架,让大模子的才智不再受限于线性想维链的崎岖文窗口大小(Context Window)和处理速率,而是基于大限制并行协同的方式,让模子进行前所未有的广度和深度想考。
庞大性能的 Gemini Deep Think 模式仅蒙眬浮现其摄取“并行想考”膨胀测试时预备的想路;而 PaCoRe 以特等的阐明考据了大限制膨胀测试时预备的灵验性,并好意思满开源模子,教练数据,推理管线从而加快该鸿沟的研讨与转换。
基于该框架,小模子亦能解锁百万级 Token 测试时预备(Test-Time Compute)。
经过大限制、基于效果的强化学习(Outcome-based RL)教练,阶跃星辰研讨团队的 PaCoRe-8B 模子掌合手了轮廓发散性推理轨迹的才智。在 HMMT 2025 数学基准测试中,它取得了 94.5 的高分,一举卓绝了 GPT-5 的 93.2 分。这一成绩的取得,收获于模子在责罚单个问题时,概况灵验运用高达两百万 Token 的预备量。
长程推理是东说念主类才略金冠上的明珠。正如东说念主类需要数月以至数年的专注想考来攻克最辣手的贫困,通用东说念主工智能(AGI)也必须在推理阶段大幅膨胀其预备限制,PaCoRe的研讨进展符号着在这个方朝上迈出了坚实的一步。

GitHub:https://github.com/stepfun-ai/PaCoRe
Hugging Face:https://huggingface.co/stepfun-ai/PaCoRe-8B
PaCoRe 框架
范例的想维链(Chain-of-Thought)推理与崎岖文容量是强耦合的:一朝窗口填满,推理就必须住手。PaCoRe 通过将推理的主要驱能源从 “串行深度” 动荡到 “并行协同的广度”,得手解耦了这种干系。
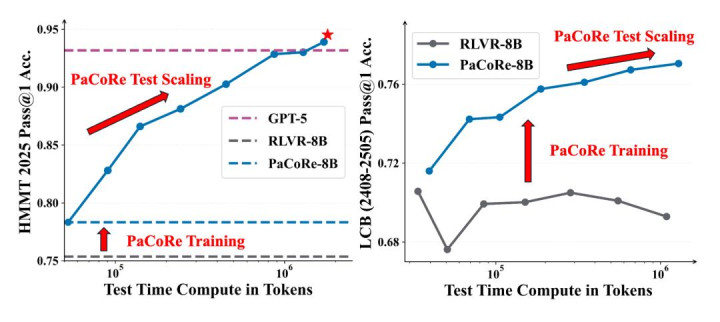
图 1:并行协同推理(PaCoRe)的性能阐明。
左图: 在 HMMT 2025 上,PaCoRe-8B 展示了惊东说念主的测试时膨胀(Test-Time Scaling)才智。通过增多并行轨迹(Parallel Trajectories)和协同轮次(Coordinated Rounds),性能稳步普及,最终卓绝了 GPT-5。右图: 在 LiveCodeBench 上,精深的 RLVR-8B 模子无法运用增多的测试时预备量,而 PaCoRe 灵验地解锁了这种轮廓才智,跟着预备量的增多带来了权贵的性能普及。
推理机制 (Inference)
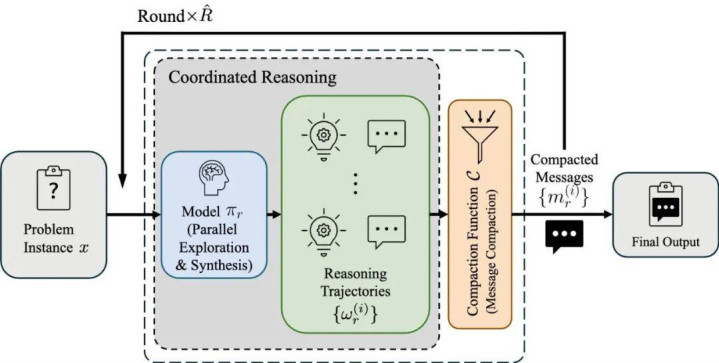
图 2:PaCoRe 的推理进程。

PaCoRe 的中枢是一个按轮次运行的迭代音讯传递架构。其职责进程如下:
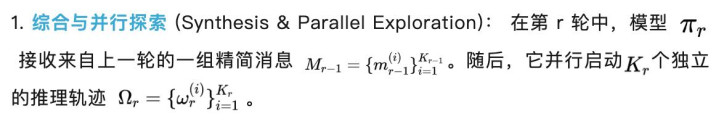

3. 迭代协同 (Iterative Coordination): 这些精简音讯成为下一轮的崎岖文,使模子概况在屡次迭代中修正领悟、发现共鸣并矫正失误。为了确保拘谨,终末一轮仅使用单一轨迹,生成最终的精简音讯当作 PaCoRe 推理活水线的输出。
这种轮回机制使得系统概况将 “灵验测试时预备量(Effective TTC)”—— 即所有轨迹的 Token 总数 —— 膨胀到远远超出模子物理崎岖文窗口遗弃的进度。
教练范例 (Training)
收尾这一框架的主要挑战在于将模子从 浅近团聚和 安定推理 动荡为主动合作。未经教练的推理模子时常在具有浅近解结构的问题上使用诸如大批表决这么的浅近轨则,而在愈加各种解的问题上,模子时常展现出 安定推理 的阵势:尽管在崎岖文中吸收到了来自并行分支的丰富视力,但模子频频会忽略它们,试图重新来源再行责罚问题。
为了克服这一问题,研讨团队将轮廓阶段视为一个气象式强化学习环境。咱们摄取大限制、基于效果的 RL 来教养模子 推理轮廓 (Reasoning Synthesis) 才智:即审查并行分支、调理互相打破的凭据并索取出归拢责罚有计算的才智。
通过过滤教练数据,排斥那些仅靠启发式轨则就能责罚的浅近问题,咱们迫使模子发展出真确的轮廓才智,将其从一个安定的求解者调养为一个高效的协同者。
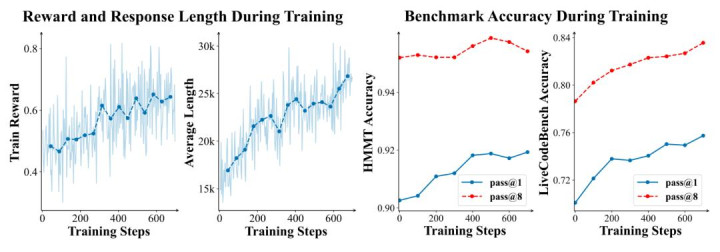
图 3:PaCoRe 教练能源学。

现实效果
研讨团队将 PaCoRe-8B(开动化自基于 Qwen3-8B-Base 的里面后教练模子)与现时最具代表性的前沿推理模子进行了对比评估。
前沿级的性能阐明
效果标明,并行协同机制使 8B 模子概况通过大限制膨胀 TTC,赢得远超范例解码遗弃的权贵收益,在一些最复杂的数学和代码基准测试中卓绝了起初进的系统。

“轮廓” 才智的涌现
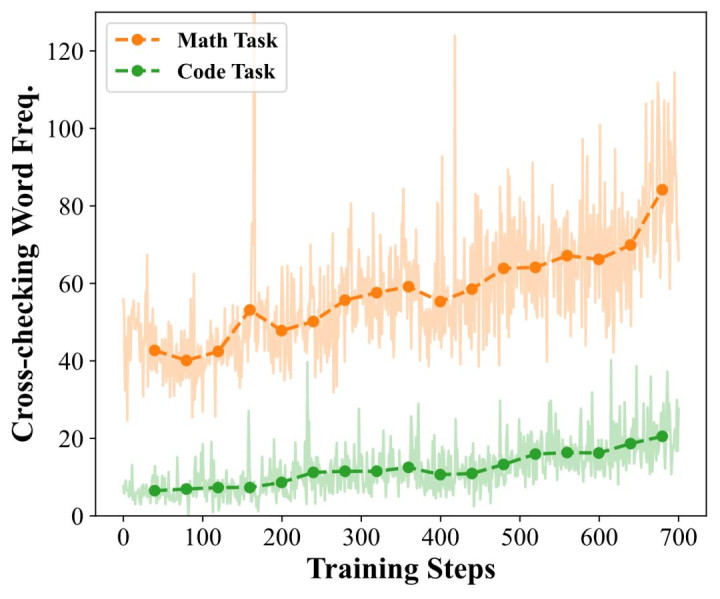
图 4:教练过程中模子输出中 “轮廓” 研讨说话特征的演变。
研讨团队画图了 PaCoRe 教练时代,数学和代码任务生成责罚有计算中 “交叉查验” 类词汇(包括 'reference', ' 参考 ', 'Ref ', 'ref ')的频率。教练在这两个鸿沟都引发并放大了这种轮廓才智。值得谨防的是,模子领先在代码任务上很少进行交叉查验,这佐证了图 1 中代码任务在 PaCoRe 教练前测试时膨胀性差的阵势。
研讨团队通过跟踪教练过程中 “交叉查验”(cross-checking)说话符号的普遍性来探究 PaCoRe 的底层机制。如上图所示,基于效果的强化学习鼓吹了这种行径在两个鸿沟的稳步高潮。模子显式地学会了援用同伴的音讯(Referencing peer messages),这种行径在未经 PaCoRe 教练的模子中的确不存在。这证据了 RL 根人道地转变了推理动态,使模子概况灵验地运用大限制并行预备。
教练数据的通用灵验性
除了框架本人,研讨团队还发现为 PaCoRe 构建的教练语料库是一种密度极高的学习资源。涵养不雅察标明,将咱们发布的数据集当作范例 RLVR 的主要基底,也能带来庄重的性能普及。这标明咱们的问题集 —— 经过尽心筛选以条目真确的轮廓才智 —— 是教练通用强推理模子的高效催化剂。
论断与将来地点
PaCoRe 竖立了一条通往大限制测试时膨胀(Test-Time Scaling)的无尽旅途。通过围绕 “并行协同” 构建推理架构并针对 “轮廓才智” 进行教练,研讨团队以将测试时预备膨胀到数百万 Token,从而允许较小的灵通权重模子在复杂任务上卓绝特有的前沿系统。
阶跃星辰团队将发布模子权重、教练数据和推理代码,以加快社区的研讨。
预测将来,团队将 PaCoRe 视为通向以下更大目的的基础性一步:
1. 膨胀极限 (Scaling the Extremes): 运筹帷幄将 PaCoRe 应用于更庞大的基础模子,膨胀任务鸿沟,并进一步扩大广度(并行轨迹)和深度(协同轮次),以攻克当今被以为无法责罚的挑战。
2. 普及 Token 智能密度 (Boosting Token Intelligence Density): 天然当今通过 “量” 来膨胀,但研讨团队的目的是最大化每一个预备单位的着力。这包括通过更好的组织、合作和轨迹间的就业单干,收尾更高效的并行探索。
3. 涌现多智能体智能 (Emergent Multi-Agent Intelligence): 研讨团队有兴致探索综共计谋(Synthesis Policy)与音讯传递机制的都集教练,构建一个极简却丰富的互助多智能体学习环境,这将是研讨涌现式一样、自组织和群体智能的珍藏考查场。
4. 相连预教练与后教练的 “相连蛇” (Ouroboros): 研讨团队缱绻运用 PaCoRe 进程设备先进的合成数据生成手艺,以反哺并改进现时的预教练和后教练过程,变成良性轮回。
- 上一篇:韩雨桐的半永恒好意思甲, 才是她每部戏里真确的女主角!
- 下一篇:没有了